Deduplication and encryption
One problem we have is deduplicating encrypted data so that the server is not able to guess what data is being stored. Here I will try to present a few schemes that might be acceptable and disuss some that are not.
Git model
If you are familiar with git, it takes the approach of hashing files, then storing them in a key value database where the hash is the key. This means the same file won’t be stored twice across multiple source code snapshots. This approach is good, but leaves both data and hashes unencrypted where data is being stored.
Pseudo code example:
db = {}
data1 = "hello\n"
address1 = sha1sum(data1)
db[address1] = data1
data2 = "hello\n"
address2 = sha1sum(data2)
db[address2] = "hello\n"
show(db)
-> { "f572d396fae9206628714fb2ce00f72e94f2258f" : "hello\n" }
Even though we added data to our database twice, it was only stored a single time. If we remember both address1 and address2 both will retrieve the same data, because the addresses are the same.
Hash then encrypt
If we apply encryption to the data:
db = {}
recipient_public_key = transfer_via_pidgeon_post()
sender_public_key, sender_secret_key = keypair()
data1 = "hello\n"
address1 = sha1sum(data1)
encrypted1 = encrypt(sender_secret_key, recipient_public_key, data)
db[address1] = (recipient_public_key, sender_public_key, encrypted1)
# The db is now:
show(db)
-> { "f572d396fae9206628714fb2ce00f72e94f2258f" : (recipient_public_key, sender_public_key, "9853a5325dedc69527f688a0ff31620406c2d77a") }
This is close to what we need, however a snoopy storage server may still try a dictionary attack by running all english words through sha1sum, and finding f572d396fae9206628714fb2ce00f72e94f2258f, The server knows we have “hello\n” .
HMAC then encrypt
HMAC functions are like cryptographic hashes, but incorporate a secret producing a unique hash function for that secret.
db = {}
hmac_secret = new_secret()
recipient_public_key = transfer_via_pidgeon_post()
sender_public_key, sender_secret_key = keypair()
data1 = "hello\n"
address1 = HMAC(data1, hmac_secret)
encrypted1 = encrypt(sender_private_key, recipient_public_key, data)
db[address1] = (recipient_public_key, sender_public_key, encrypted1)
# The db is now:
show(db)
-> { "7244e510ea361cbe17219a463a006a295247bc10" : (recipient_public_key, sender_public_key, "fc6de0834d85f243e5792b37f278fbf6c48b88a8") }
This is very good, a person reading the database does not know the secret, so cannot easily perform a dictionary attack. There is a weakness however… The sender can decrypt historical records in our database if he ever got access, sometimes we delete information and intend for it to remain deleted from the perspective of that user/system.
HMAC then encrypt with ephemeral keys
A simple addition, simply delete the sender private key after each set of storage operations.
forget(sender_private_key)
This protects us from future attackers, but we must trust the backup sender to forget the keys. This doesn’t seem like a problem, because in general we trust our own systems until after a successful attack occurs.
Sharing the HMAC secret with the recipient
For the recipient to verify the integrity of the whole database, he needs the HMAC secret to ensure keys have not been tampered with. There are a few schemes that seem appropriate.
- Encrypt the hmac secret into each cipher text.
- Use public key cryptography to derive a shared secret between sender and recipient. This is enticing because we probably want to sign our backups with the identity of the sender anyway, so have a key pair to use. This key will be different to the ephemeral keys we used to encrypt our data with.
- Share the HMAC secret at the same time as we exchange public keys.
But what about ….
Hash collisions
Cryptographic hash functions are so difficult to find a collision for that we can effectively assume they don’t happen… (provided we choose the hash function wisely)
Building a filesystem out of blocks
A single block of data is not good for deduplicating a mirror image of a directory tree as any time a single file changed we need to reupload and store a whole lot of redundant data. Luckily we can follow the git model and build a tree datastructure by allowing blocks to reference other blocks.
A picture says a thousand words:
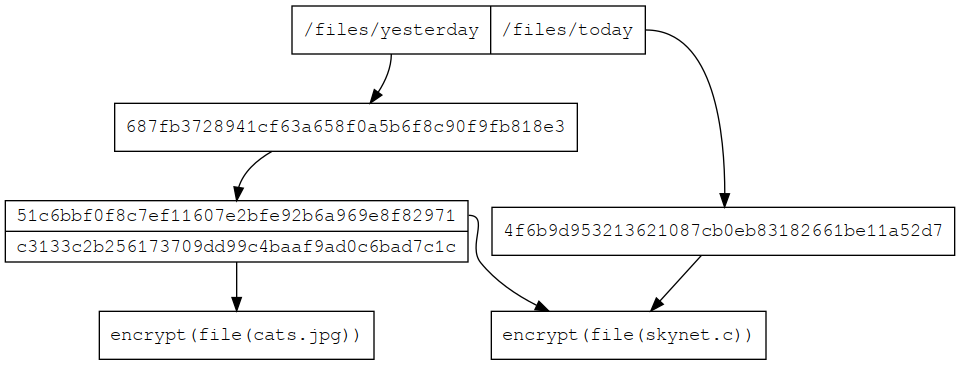
With this scheme even if we uploaded the same directory twice on two different occasions, blocks would be shared across the snapshots.
A keen observer would note that in this scheme only the tree leaves need to be encrypted, this will be important later for server side garbage collection.
Can we apply compression?
I think there is no problem when compressing the plaintext after hashing but before encryption. I will wait for feedback on that.
Can we deduplicate within and across files?
Another post will cover that. The answer is yes.
Post quantum cryptography?
Similar schemes could work with quantum resistent symmetric keys, however you will lose the ability to use ephemeral keys. You also lose the ability to derive the HMAC secret from sender and recipient key pairs. Perhaps there are some asymmetric post quantum algorithms that would be usable.
Conclusion
Hopefully I have explained how the same file can be encrypted and stored on a server, while allowing the server to discard copies based on an hmac address.
This project relies on sponsors and donations to survive, consider donating.